
Self-guidance, or simply guidance, is fundamental to systems for image generation including both diffusion-based image generators, such as the well known DALLE generator, and autoregressive image generators such as CM3leon. A technical definition of guidance is given below. While Guidance is fundamental to image generation, the semantics is unclear. This post argues that guidance causes image generation to capture “essence”. This is also a fundamental motivations of human drawing and painting (human art). An empirical test of this claim is to apply guidance to a system trained only on photographs. The guidance-as-essence hypothesis would predict that, even when trained only on photographs, a model that generates images through guidance can generate drawing-like images. Drawings capture essence.
To define guidance I will assumed we have trained a model that computes a probability of images given textual descriptions 





The idea here is that we want the distribution to favor images corresponding the text 


Now the question is whether the modified distribution 
I will also suggest that the use of guidance interacts with the quantitative metrics for image generation. The most natural metric for any generative model (in my opinion) is cross entropy. Base models are trained by optimizing cross entropy loss in both image models and language models. For language models it is traditional to measure cross entropy as perplexity or bits per byte. For images it is traditional to measure cross entropy in bits per channel as defined by the following where 

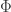
![\mathrm{Loss}(\Phi) = \frac{1}{C}\; E_{I,T \sim \mathrm{Pop}}[\;-\log_2\;P_\Phi(I|T)]](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BLoss%7D%28%5CPhi%29+%3D+%5Cfrac%7B1%7D%7BC%7D%5C%3B+E_%7BI%2CT+%5Csim+%5Cmathrm%7BPop%7D%7D%5B%5C%3B-%5Clog_2%5C%3BP_%5CPhi%28I%7CT%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Bits per channel measures the ability of the model to represent the true conditional distribution 
That said, I still feel that the FID metric is not well motivated. I would suggest measuring both the conditional bits per channel as defined above and the unconditional bits per channel and summing those scores as a measure of the “correctness” of guided image generation.
The paper on CM3leon has a nice discussion relating guidance in image generation to a form of top-k sampling in language generation. Top-k sampling also modifies the generation process in a way that is not faithful to simply sampling from a conditional distribution. Top-k sampling in language generation exhibits the same coherence-diversity trade of (as a function of 
The bottom line for this post is the hypothetical relationship between guidance and art and the prediction that guidance can result in drawing-like images even when the generating model is trained only on photographs.

I haven’t kept up with text-to-image generation; is it the case that current models produce a line drawing or a sketch when $s$ is turned way up? Or does it produce a more proto-typical example of the object than you’d expect to see in real life (like your example of the drawings in bird-watcher’s field guides)?
I am very sympathetic to the Cognitive Semantics approaches which claim that simple spatial metaphors underlie lots of language, as proposed by people like George Lakoff and (a different to me) Mark Johnson. They draw abstract sketches to show (metaphorical) spatial relationships; see https://en.wikipedia.org/wiki/Image_schema for a few examples. It would be very cool if a machine could produce such sketches; and truly amazing if they “emerged” from a text-to-image generator with the appropriate parameter settings.
On a vaguely related issue: Melanie Mitchell pointed out to me that all our models learn concepts by abstracting them from complex language, while children almost certainly have all or most of the concepts before they learn language.