
While teaching reinforcement learning I kept asking myself what AlphaZero teaches us about RL. That question has lead to this post. This post generalizes AlphaZero to a larger class of RL algorithms by reinterpreting AlphaZero’s policy network as a belief function — as the probability that 

A fundamental question is whether belief gradient is a better conceptual framework for RL than policy gradient. I have always felt that there is something wrong with policy gradient methods. The optimal policy is typically deterministic while policy gradient methods rely on significant exploration (policy stochasticity) to compute a gradient. It just seems paradoxical. The belief gradient approach seems to resolve this paradox.
The action belief function and a belief gradient algorithm. For a given state in a given Markov decision process (MDP) with a finite action space 




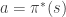

To make the mathematics clearer I will assume that the belief
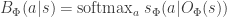
where 


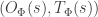




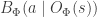

(1)

This is just the gradient of a cross-entropy loss from the replay buffer to the belief
Some AlphaZero details. For the sake of completeness I will describe a few more details of the AlphaZero algorithm. The algorithm computes rollouts to the end of an episode (game) where each action in the rollout is selected based on tree search. Each rollout adds a set of pairs 

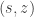


Improved generality. The abstract mathematical formulation given in equation (1) is more general than tree search. In the belief
A belief gradient theorem. While I have reinterpreted policies as beliefs, and have recast AlphaZero’s algorithm in that light, I have not provided a belief gradient theorem. The simplest such theorem is for imitation learning. Assume an expert that labels states with actions. Optimizing the cross-entropy loss for this labeled data yields a probability
